自然语言处理的演进:从碎片化人工智能到基础模型
定义
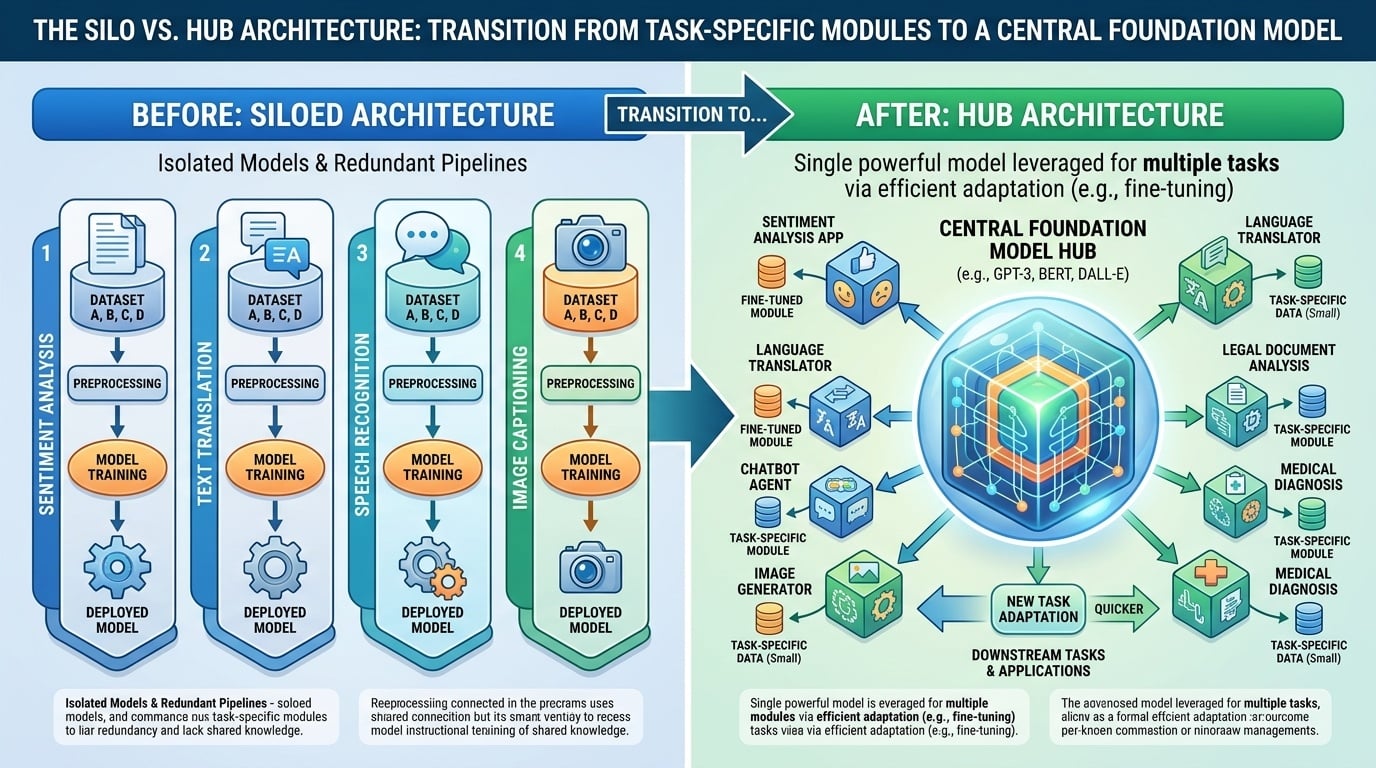
- 碎片化人工智能:一个由独立、专用的神经网络架构所定义的时代,这些架构专为特定任务(如序列标注或分类)而设计。
- 基础模型:一种统一的、单一的Transformer架构,将所有语言问题都视为生成式的文本到文本序列 $x \rightarrow y$。
核心概念
- 架构整合: 历史上,NLP需要定制化的流水线(如用于命名实体识别的Bi-LSTM,用于情感分析的CNN)。大语言模型将这些孤岛式结构合并为一个单一的主干网络,其中相同的权重被用于所有任务。
- 统一接口: 大语言模型用自然语言接口取代了专用的“输出头”(例如,三分类Softmax)。输入和输出始终是字符串,使模型能够理解 意图 而非 格式。
- 知识迁移: 传统模型在每个任务上都是“白板”。大语言模型优先考虑 泛化优先,即具体任务只是对预先存在的、稳健的语言内部表征的应用。
历史背景
- 2018年以前: 任务隔离要求使用不同的损失函数 $\mathcal{L}_{task}$ 训练不同的模型。
- 现代时代: "文本到文本"范式允许单个模型(例如,Llama-3)通过零样本或少样本提示来切换任务。
Python 实现对比